ReAct
This Research Paper introduced a new framework called ReAct in Prompt Engineering where Large Language Model (LLM) are used to generate both reasoning traces and task-specific actions in a interleaved manner.
Generating the Reasoning allows the LLM to induce, track and update action plans and even handle exceptions. The action step allows to interface with and gather information from external sources such as knowledge bases or environments.
The ReAct framework can allow LLMs to interact with external tools to retrieve additional information that leads to more reliable and factual responses.
ReAct is able to outperform most state of the art baselines and decision making tasks. It also leads to improved human interpretability and trustworthiness of LLMs. The authors have concluded that both ReAct and Chain Of Thought (COT) produces the best results as it allows to get the best of internal and external knowledge during reasoning.
ReAct is inspired by the synergies between “acting” and “reasoning” which allow humans to learn new tasks and make decisions or reasoning.
Chain Of Thought (COT) has show to have great reasoning traces and ability of generating answers with Arithmetic and commonsense questions, but it lacks the ability to integrate external knowledge which can lead to fact hallucination and error propagation
ReAct is a general paradigm that combines reasoning and acting with LLMs. ReAct prompts LLMs to generate verbal reasoning to create, maintain, and adjust plans for acting while also enabling interaction with external environments to incorporate additional information.

In ReAct the model generates problem solving trajectories in correspondence to the observation from the environment that is being interacted with. In essence ReAct can retrieve information to support reasoning, while reasoning helps to target what to retrieve next.
Results on Knowledge-Intensive Tasks
We can also observe that ReAct outperforms CoT on Fever and lags behind CoT on HotpotQA. A detailed error analysis is provided in the paper. In summary:
- CoT suffers from fact hallucination
- ReAct’s structural constraint reduces its flexibility in formulating reasoning steps
- ReAct depends a lot on the information it’s retrieving; non-informative search results derails the model reasoning and leads to difficulty in recovering and reformulating thoughts
source: promptingguide.ai
Prompting methods that combine and support switching between ReAct and Chain Of Thought (COT)+Self Consistency generally outperform all the other prompting methods.
Results on Decision Making Tasks
The paper also reports results demonstrating ReAct’s performance on decision making tasks. ReAct is evaluated on two benchmarks called ALFWorld (text-based game) and WebShop (online shopping website environment). Both involve complex environments that require reasoning to act and explore effectively.
source: promptingguide.ai
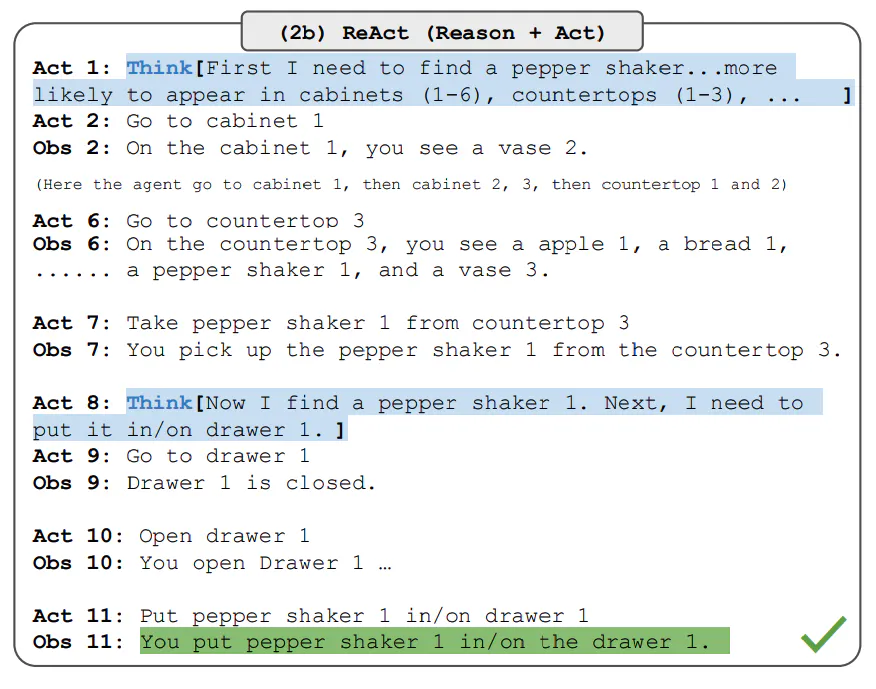
ReAct outperforms Act on both ALFWorld and Webshop. Act, without any thoughts, fails to correctly decompose goals into subgoals. Reasoning seems to be advantageous in ReAct for these types of tasks but current prompting-based methods are still far from the performance of expert humans on these tasks.
References